How To Poke Around OBIEE on Linux with strace (Working with Unsupported ODBC Sources in OBIEE 12c)
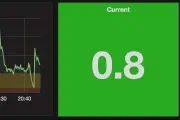
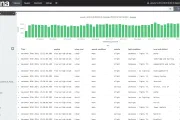
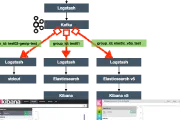
This post originally appeared on the Rittman Mead blog. OBIEE 12c (and 11g and 10g before it) supports three primary ways of connecting to data sources: Native Gateway, such as OCI for Oracle. This …