Why is kcat showing the wrong topics?
Much as I love kcat (🤫 it’ll always be kafkacat to me…), this morning I nearly fell out with it 👇 😖 I thought I was going stir crazy, after listing topics on a broker and seeing topics from a …

Much as I love kcat (🤫 it’ll always be kafkacat to me…), this morning I nearly fell out with it 👇 😖 I thought I was going stir crazy, after listing topics on a broker and seeing topics from a …
 Blogging
Blogging



 DuckDB
DuckDB
 DuckDB
DuckDB




 Postgres
Postgres





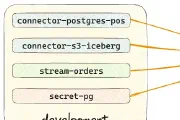 Decodable
Decodable

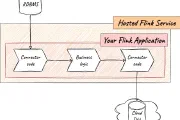
 Apache Flink
Apache Flink
 Apache Flink
Apache Flink
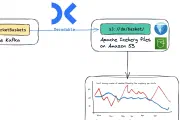 Apache Kafka
Apache Kafka

 RSS
RSS


 Apache Flink
Apache Flink

 Kafka Summit
Kafka Summit






 Antora
Antora
 GitHub
GitHub
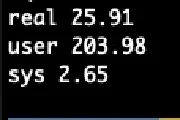
 Antora
Antora



 Flink JDBC
Flink JDBC

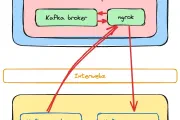
 LAF
LAF
 LAF
LAF
 LAF
LAF